

By Phillip Gales · May 2026
The accounting
Three weeks ago I quoted six to nine months for a product. We'd need a team, I said: twelve people, half of them senior engineers. The hedge fund use case was genuinely complex.
Three weeks later, by my count, the product is substantially built.
By me. By two AI agents. By, in total, about forty hours of my attention.
I want to be careful with that figure, because it sounds like the kind of thing one says on LinkedIn to attract investors and disbelief in roughly equal measure. So let me anchor it. In the last twenty-one days, working from a single repository with two AI coding agents and no other contributors on this part of the codebase, I added 128,506 lines of code to production paths, touched 658 files, made 28 thesis-tagged commits, and accumulated 144 distinct documentation files totalling 709,673 words. That last figure is, for those keeping score, eight times the length of Moby Dick. Roughly fifteen hundred book pages of product strategy, architectural design, and implementation plans, written almost entirely by AI agents and reviewed at the gates by me. Total cost of the AI subscriptions that drove the work, prorated for the period: $238.
This is not an article in praise of AI agents in the abstract. The first piece in this series argued the architectural case for two-agent peer review on epistemic grounds. That argument is upstream of what follows. This article is the demonstration. It is what happens when you take the architecture from the first piece and run it, in earnest, on a product of non-trivial complexity, for three weeks.
I am going to walk you through the eight stages it took to build the thing. I will tell you, at each stage, what was produced, by whom, and how long it took. I will end with the numbers added up. The numbers are the point.
What we built, briefly
Thesis Labs is a research workflow tool for hedge fund analysts. It replaces $500–$2,000 per hour expert-network calls with on-demand synthetic interviews against a pool of 301,191 AI agents, each instantiated with their own demographic profile, occupation, and persona. Six tabs: thesis framing, channel checks, expert calls, pressure-testing, summarisation, consolidation. A junior analyst can frame a thesis at nine in the morning and have a memo before lunch.
This article is not about Thesis Labs. Anyone interested in the product itself can stop reading here and find me on email. This article is about how the product got built.
The eight stages
Every product team I have ever seen, from a four-person start-up to a Fortune 500 platform group, runs some version of the same eight-stage process from idea to live feature. Concept → Product Research → Product Brief → Dev Work Scope → Dev Implementation → Dev QA → Product QA → Release Notes. The stages are not always called by these names, and the order shuffles slightly, but the structure is essentially universal. Different roles own different stages, and the hand-offs between them are where the delay accumulates.

What is novel about the last three weeks is not the structure. It is that, of the eight stages, exactly one is now reliably and substantively human work. The other seven are done by agents, with me at the gates. Below, what each stage looked like for the Thesis Lab build, in order.
Stage 1 — Concept
This is the only stage that is almost entirely human. The concept came out of conversations in March with hedge fund analysts who were unhappy with the economics of expert-network research. Twenty-minute calls cost $500. The question always took longer than the answer. The expert was often a third of the way down the relevance ladder. The procurement cycle to get them on the phone took days. There was a product opportunity in that gap.
The concept stage took perhaps four hours of my time across two weeks. Six pages of unstructured notes, two whiteboard photos, a working title. Just enough that an agent could pick up the synthesis next.
This is the part where humans still genuinely do better than agents. The framing of which problem to solve at all is downstream of taste, judgment, and reasonably high-context knowledge of what the customer wants but cannot articulate. Agents can, and do, generate concepts on prompt; they are not, yet, deciding which concept matters. Concept is the human's stage. It also happens to be the smallest stage, by volume, in the entire pipeline.
Time elapsed: about a week of low-intensity thinking. Phillip-time: ~4 hours. Output: six pages of notes.
Stage 2 — Product research
This is the first stage where agents do the heavy lifting, and they do it transformatively well.
The Thesis Lab research corpus, accumulated over the three-week window, contains seventeen distinct research documents, four PowerPoint decks, a hedge-fund-junior-analyst journey map, and a reasonably exhaustive cognitive-science deep-dive on how elite investors actually make decisions under uncertainty. None of these were written by me. All of them were either written by Claude or, in the case of the synthetic-user research, generated by FishDog's own synthetic-expert platform with Claude orchestrating the queries.
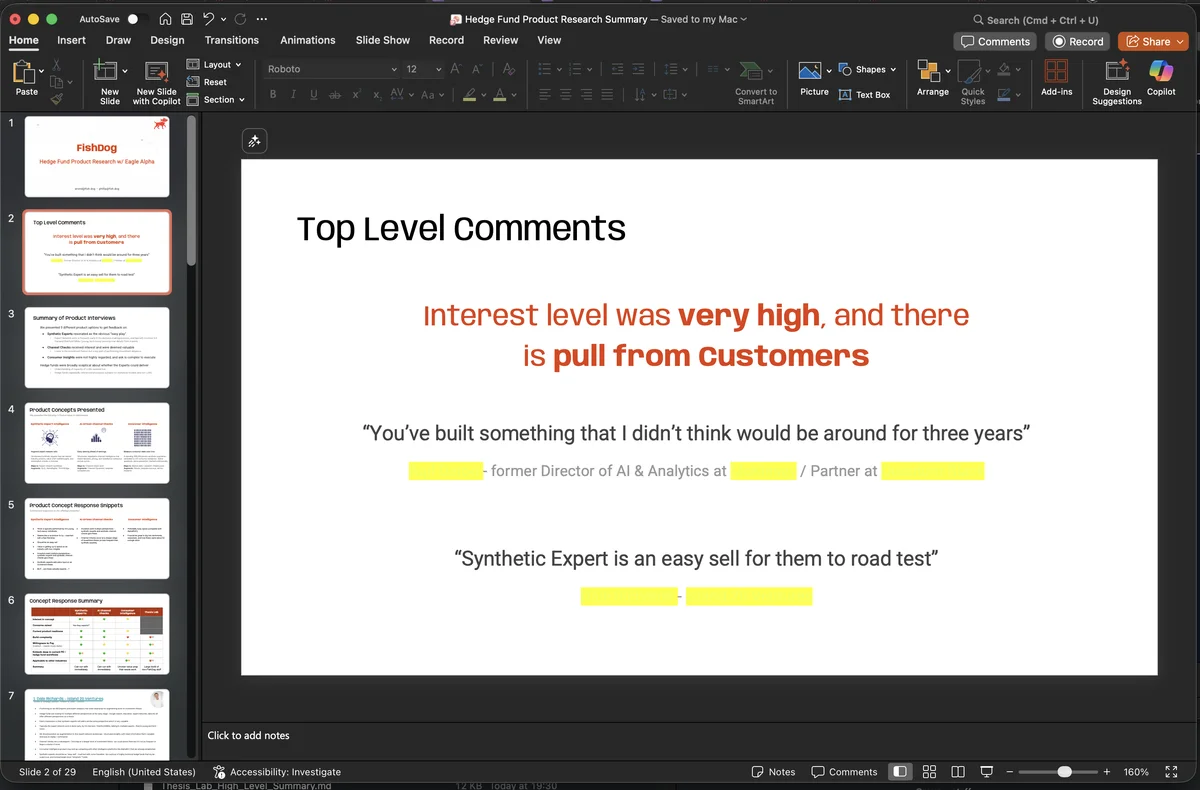
The single most useful artefact in this stage was a hundred-page hedge-fund-junior-analyst journey map. I asked Claude to study the existing literature on how junior analysts work, run synthetic interviews against forty FishDog personas matching the target buyer profile, synthesise the friction points, and propose a structured journey from morning coffee to evening memo. It came back, three hours later, with the journey map and a set of trade-off observations about which friction points were real, which were artefacts of legacy expert-network constraints, and which were latent demand that no existing tool was meeting.
I read the document, in detail, in about five hours. Reading time is now substantively a bigger time commitment than writing time, because the agents write so much faster than I can read. This will become a theme.
The synthetic-user research is where FishDog earned its place in the workflow. Rather than commission a $40,000 user-research firm to produce a buyer-persona report on hedge fund analysts, I asked FishDog's own agent platform to instantiate a panel of forty buyer personas across hedge funds, private equity, venture, consulting, and healthcare research. Claude wrote the interview guide. FishDog ran the interviews. Claude synthesised the transcripts into a buyer-persona PowerPoint with named personas, jobs-to-be-done, and willingness-to-pay estimates. The whole thing took less than four hours.
Stage 2 produced, in total, the source-of-truth strategy folder: 78 files, roughly 63,000 lines of research output. Phillip-time across the stage: about ten hours, mostly reading and prompting. Wall-clock time: about a week.
Stage 3 — Product brief
The product brief stage is where product research gets compressed into a single, opinionated document that says: here is what we are going to build, here is why, and here is what the user does. For Thesis Lab, that document is `THESIS_LAB_MULTI_SUBJECT_PRODUCT_BRIEF.md`. It is 4,414 lines, 44,173 words, and 336 KB. It is, by length, materially longer than most novels.
I will say, quietly, that this is the artefact I was most surprised by. I have written product briefs in my career. I have read hundreds. I have never, before this project, encountered a brief that ran to 44,000 words and remained, throughout, useful. The reason this one does is that it was not written by a human under deadline pressure. It was written by Claude over the course of a Tuesday afternoon, then critiqued by Codex on a Wednesday morning, then revised by Claude on Wednesday afternoon, and so on for four full review cycles, each one adding precision, removing ambiguity, and surfacing cases the previous cycle had missed.
The mechanic of that loop is the subject of a forthcoming piece in this series, so I will not dwell on it here. The relevant point for the present article is that the brief locked, after four cycles, with twelve architectural decisions explicitly enumerated, each one referencing the user need that motivated it, the technical approach that satisfied it, and the trade-offs it foreclosed. I read the locked brief in about two hours. I had, on inspection, perhaps three substantive comments. The rest was, as far as I could tell, correct.
Across the three-week window, the project accumulated eighteen distinct product briefs and workscopes, totalling roughly 24,000 lines of architectural documentation. Each was written by an agent, reviewed by another agent, and ratified by me at a review gate. Phillip-time on briefs across the period: about six hours, almost entirely reading.
The salient observation here is the inversion. When humans wrote briefs, the bottleneck was authorship: composing a coherent document from scattered inputs took days. Now the bottleneck is reading: agents can write a 44,000-word brief in an afternoon, and the limiting resource is whether anyone can read it carefully enough to catch the errors before the implementation begins. This is the first place in the project where my time as a human became, structurally, the constraint.
Stage 4 — Dev work scope
A product brief tells the product team what to build. A dev work scope tells the dev team how. The two are different documents, written for different audiences, in different registers. Conflating them is one of the more reliable ways to ship the wrong feature.
For Thesis Lab, the major work-scope document is `Recruitment_Architecture_Product_Brief.md` — a slight misnomer, since it is in fact the dev work scope for the recruitment subsystem. 2,074 lines. 27,816 words. It enumerates the changes to the database schema, the routing layer, the recruitment workers, the persona-framework microservices, the test fixtures, and the migration strategy. It also enumerates the things that should not change, and why, which is the single most useful section of any work scope and the one most often missing from human-authored versions.
The work scope was written by Codex, which lives in the codebase and knows what is actually there. It was reviewed by Claude, which does not live in the codebase and therefore catches things Codex assumed. Three review iterations. By the third iteration, Claude was generating diminishing returns and I called it.
Beyond the recruitment work scope, the project produced eighteen workstream implementation plans, organised as `WS1` through `WS11` plus six tab-specific UI plans. Each plan ran between 800 and 2,500 lines. Each followed the same structure: locked decisions, scope boundaries, file-level change list, test plan, rollout plan, rollback plan.
The defining feature of the work-scope stage in our pipeline is the review-gate discipline. Three explicit human review gates — G1, G2, G3 — punctuate the plan. G1 is at scope lock, before any code is written. G2 is at architectural lock, after the initial implementation skeleton is in place. G3 is at handoff, before the work goes live. At each gate, I read the relevant artefacts, locked or amended any decisions that needed my input, and signed off. Twelve architectural decisions were locked across the three gates for the recruitment subsystem alone.
This stage is where my time concentrated. Phillip-time across the period: about ten hours of architectural review, plus six more on the gates themselves. By far the highest-leverage sixteen hours I have spent in 2026. Not, for the avoidance of doubt, what I imagined founder work looking like.
Stage 5 — Dev implementation
This is the part where the agents work and I watch documentaries.
I am, slightly, exaggerating for effect. I am also, slightly, not.
Once the work scope is locked, Codex implements. The instructions, refined over four months of using this setup, are simple: build the work scope. If you need a decision from me, ask. If you need a database migration, tell me before you run it. Otherwise, continue. In practice, Codex builds for thirty to forty minutes, then surfaces a question or completes a workstream and waits for my acknowledgment, then continues. I provide the acknowledgment, the question, or the trade-off. The agent resumes.
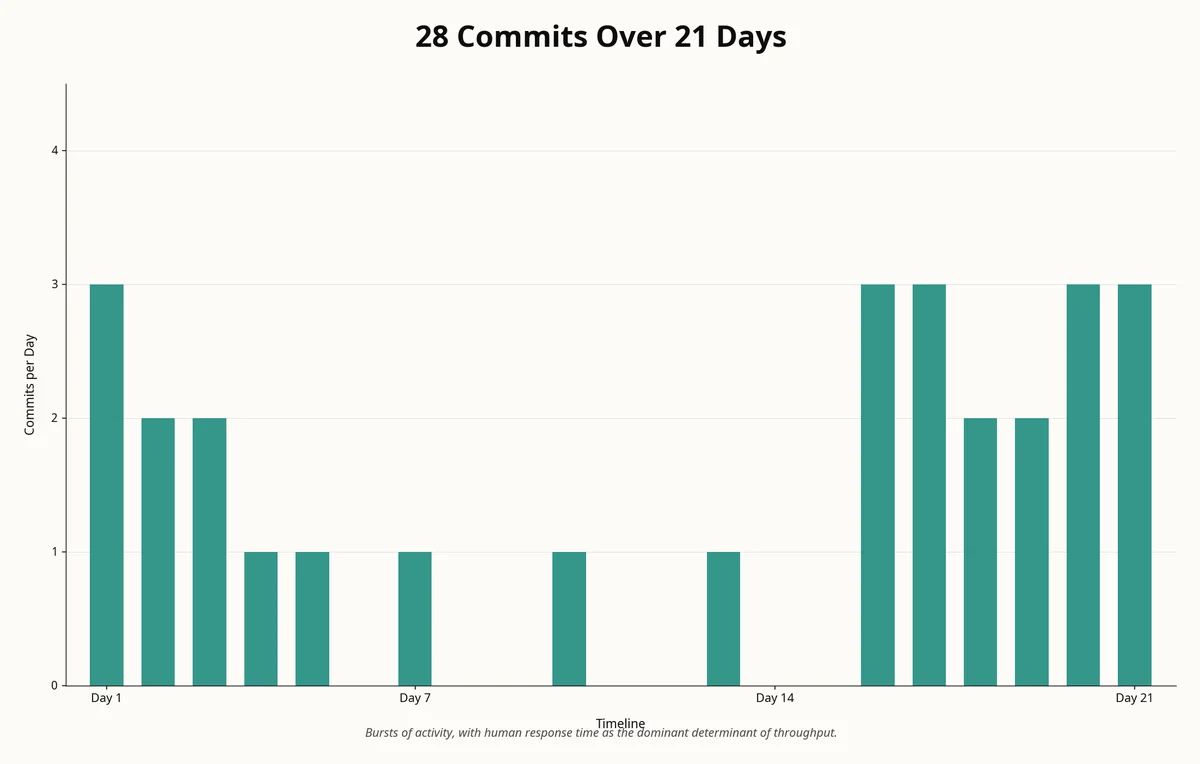
Across the three weeks, the implementation produced 28 thesis-tagged commits, touched 658 files, added 128,506 lines and removed 5,280, for a net delta of 123,226 lines. Translation: a third of everything that changed in the entire walnut_commission codebase during the window — 34% of all lines added across the repo — went to this single product. The split across languages and file types looked like this:
85,243 lines of Python — production source, tests, and scripts
11,948 lines of HTML and Jinja templates
3,565 lines of JavaScript and CSS
12,902 lines of curated YAML data, the bulk of which is the Role Taxonomy seed (we will return to this)
4 database migrations
The honest description of this stage is that it took a great deal of agent time, very little of my time, and produced a great deal of code. The dishonest description is that it was effortless: the cognitive cost on me during this stage was real, just compressed. For about ten percent of the working day during the implementation window, I was doing intense, irreducible thinking on architectural decisions Codex had surfaced that neither agent could resolve. For the other ninety percent, I was idle in the specific way you can only be idle when your contributions are gating someone else's productivity. This is its own problem and the subject of a later piece in this series.
Phillip-time on implementation: maybe six hours. The code wrote itself.
Stage 6 — Dev QA
Codex writes its own unit tests and smoke tests. This is non-negotiable in our setup, and it is the single biggest structural difference between this pipeline and a human dev team. Where this approach breaks down — at the edges that unit tests cannot reach, the user interface, the orchestration of multiple services in concert, and the cases where a product behaves correctly under test but wrongly in front of a real user — is the subject of the next piece in this series.
Across the three weeks, the implementation produced 9 dedicated test files totalling 2,152 lines of test code, plus inline test scaffolding sprinkled across the production source. Every database migration ships with a fixture. Every API endpoint ships with at least one integration test. Every recruitment-architecture change ships with a smoke query that verifies, against the live agent pool, that the change does what it claims.
The illustrative feature here is the Multi-Subject Conformance Audit: dev infrastructure whose entire job is to ensure the data underlying Thesis Lab stays high-quality across upstream microservices. Fourteen dev-side documents. Roughly 25,000 lines of audit reports. Three phases of conformance testing. 1,741 lines of audit orchestration code. None of this is glamorous. All of it is necessary. None of it would have been built, by a human team, in three weeks.
Phillip-time on dev QA: about three hours, mostly spot-checking outputs. The agents, as far as I can tell, mostly QA each other.
Stage 7 — Product QA
The most novel part of our pipeline lives at this stage. The next piece in the series, Product Unit Tests: A Missing Layer of QA in the Age of AI Engineers, defines and defends the term. The gist here.
A unit test, written by a developer, asks: does this function return what I expect. A smoke test asks: does the system stay up under load. Neither asks the question that matters most for product correctness — if a user clicks through this flow, does the experience match what the brief promised. That question, until recently, was answered by a human walking through the product, clicking, observing, and complaining when something looked wrong. Call the executable version of that walk a product unit test. It is the missing layer between smoke tests and human walkthroughs, and it is now done by an agent.
Claude does this, in our pipeline, via a headless browser. We give it a test login. We give it the product brief. We give it the relevant tab. It logs in, walks through the user flow, observes the result against the brief, and reports any mismatch. We can run this on every change. We can scale it across all six tabs. We can include it in continuous integration.
This is, I think, an important development, and the next article will argue why. For the present article, the relevant point is that product QA, in our pipeline, is now done by Claude. Phillip-time on product QA across the three-week window: less than two hours. Most of which was watching it work, in the way that a manager watches a competent junior do a job they have done many times.
Stage 8 — Release notes (and the closer)
The final stage of any feature is the release: the moment the code goes from a branch to production, with notes that explain to users what changed and why. For most of the Thesis Lab features, the release notes were boilerplate. For one, they were the reason the entire build worked at all.
On the morning of the seventh of May, I noticed something in the production data that should not have been there: every Thesis Lab research group, across eleven distinct user requests, was returning zero participants. Not few. Zero. The recruitment system was, with perfect consistency, finding no matches. We had a product that did not work.
I asked Claude to diagnose the failure. By 8:46 that morning, there was a 24,000-line diagnosis document on my desk: `Recruitment_Failure_Diagnosis_2026-05-07.md`. The cause was a vocabulary mismatch. The LLM was emitting role labels in vernacular English ("supply chain director", "senior procurement manager", "head of operations") and the agent pool was indexed against the canonical Bureau of Labor Statistics taxonomy (Industrial Production Manager, Logistics Manager, Purchasing Manager). The two vocabularies didn't intersect at all on the requests we'd been running.
By 9:11 the same morning, Claude had produced `Recruitment_Failure_Product_Brief.md`, a four-tier fix proposal. By 8:07 that evening, Codex had produced `Role_Taxonomy_Seed_Workscope.md`, a detailed scope for authoring the bridge between the two vocabularies. By 1:16 the next afternoon, Claude had produced an eight-phase work plan for actually writing the bridge. By 2:26 that afternoon, the seed was authored: 301 role archetypes, 2,736 user-vernacular aliases (including British and American English variants), 100 percent coverage of the BLS occupational labels (433 of 433), 16 of 16 industry categories. By 3:22 that afternoon, the seed was loaded to production and validated against the original failure fixture.
The original failure case — the one that had returned zero participants on the morning of the seventh — now recovered a 531-agent recruitable cohort.

From bug-noticed to fix-in-production: under 48 hours. Phillip-time across the entire arc: about five hours, almost all spent at the three review gates that punctuated Claude's work. Three architectural decisions locked, twelve sub-decisions ratified, one production failure fixed.
The release notes for this feature say, in the official version, that the recruitment subsystem now bridges vernacular and canonical vocabulary via a curated 301-archetype seed. The unofficial version is that two AI agents and a human, working over 48 hours, fixed the most consequential bug in the product, and the human's contribution consisted of saying yes, ship it at three different points.
This is, in miniature, the entire build.
The numbers, contrasted
The Thesis Lab build, as documented above, took 21 days of wall-clock time, about 40 hours of my attention, and $238 in AI subscription costs prorated for the period ($120/month Claude plus $220/month ChatGPT, divided into 21 days).
By way of comparison, the most accurate human-team estimate for the same scope of work — produced before the build began, by me, in conversation with a channel partner — was six to nine months and twelve people. At fully-loaded engineering rates (call it $250,000 per engineer per year), twelve people for three weeks would have cost roughly $173,000. For six months, roughly $1.5 million.

Set the human-team estimate aside, because it is a counterfactual and counterfactuals are unfalsifiable. What is not a counterfactual is what actually happened over the three weeks: the codebase grew by 128,506 lines on Thesis Lab paths, 658 files were touched, 28 thesis-tagged commits landed, and 144 documents totalling 709,673 words were generated. Eight times the length of *Moby Dick*. Roughly fifteen hundred book pages. Reading the documentation alone, at a normal reading speed, would have taken about fifty hours.
The implied multiplier on my time, against any baseline I can construct, is between 60× and 80×. Forty hours of my attention, in this configuration, produced output that would have required between two and a half thousand and three thousand two hundred hours of human team-time to produce the conventional way. Roughly 3,200 lines of code per hour of my attention, if you reduce it to that ratio. The number is so absurd I do not believe it, even though I have just generated it from the git log.
The cost ratio is more striking still. $238 of AI subscriptions versus the $50,000–$100,000 range a comparable team would have cost, fully loaded, over the same three weeks. About one third of one percent of comparable team cost. In a world where the constraint on most start-ups is runway, this is not a marginal change. It is a reordering.
What this changes
It would be reasonable to read the above as a productivity story. Phillip used two AI agents and built a product faster than expected. Useful. Move on. I think it is more than that, and the more is roughly the thesis of the first piece in this series, demonstrated rather than argued.
The eight-stage structure of product development, set out at the top of this article, is universal. Every product team runs some version of it. What has changed in the last twenty-one days is not the structure. It is that seven of the eight stages are now genuinely done by agents, with humans only at the gates and at the irreducible decisions. Concept is still mine. Everything else is, in the day-to-day, Claude's or Codex's, with my contribution narrowing to architectural review, irreducible trade-off arbitration, and the small set of corporate-context decisions the agents cannot make from inside the work.
This is not a productivity tip. It is a structural observation. The pipeline that produces a hedge-fund-grade product in three weeks is not faster human work. It is mostly not human work. The role of the human is not to do the stages faster; it is to do fewer of them, at gates, in higher-stakes increments. My forty hours, across this build, were not forty distributed hours of doing-the-thing. They were forty highly concentrated hours of deciding-the-thing, with the doing happening, asynchronously, by agents.
What this implies for engineering organisations, for hiring, for valuations of teams as intellectual property, and for the unit economics of starting a software company, is large enough that I am not going to attempt to enumerate it here. The first piece in this series gestured at part of it: as frontier-model capability grows, peer-LLM verification becomes the only verification layer that scales. The present article suggests something complementary: the structure of work itself shifts, with the human's contribution becoming progressively narrower, more concentrated, and higher-stakes. Most of the loop, by volume, no longer touches the human at all.
A note on the discomfort
I want to close on the bit I am most unsure about, which is the bit I find most uncomfortable.
Forty hours of my attention produced output that would have required a small team for six months. The senior engineers, designers, and PMs who would have built that team are very good at what they do; this build does not invalidate them. It does invalidate the organisational shape their craft has assumed for the last twenty years. I do not, most days, know what to do with that. I do, however, know that the shape is changing.
I am not entirely thrilled about this, for reasons I will get to in a later piece. I am, however, certain it is happening. The Thesis Lab build is the proof I am offering.
Closing
Twenty-one days. Forty hours. 128,506 lines of code. 709,673 words of documentation. $238 in subscriptions. One product, in production, doing what the brief said it would do.
The next piece in this series — Product Unit Tests: A Missing Layer of QA in the Age of AI Engineers — covers the most novel mechanism in the pipeline above. The mechanism that means we can now ship a 128,506-line product in three weeks and have it actually work when a real user clicks on it. We will give that mechanism a name, define it carefully, and argue why it deserves a layer of its own in the engineering testing stack.
Until then: this is what twenty-one days of two-agent work looks like, with the receipts.
Phillip Gales is the founder of [FishDog](https://fish.dog), a synthetic market research platform. This is the second in a six-part series on building software with AI agents. The previous piece — Two AI Agents Are Better Than One: Why I Stopped Trying to QA Codex Myself — argued the architectural case for two-agent peer review on epistemic grounds. The next piece — Product Unit Tests: A Missing Layer of QA in the Age of AI Engineers — names a missing layer of the engineering testing stack.